
Similitude Based Segment Graph Construction and Segment Ranking for Automatic Summarization of Text Document
DOI:
https://doi.org/10.48048/tis.2022.1719Keywords:
Single document summarization, Graph-based summarization, Graph scoring, Sentence segment scoring, Information gain ratioAbstract
With the increase in the amount of data and documents on the web, text summarization has become one of the significant fields which cannot be avoided in today’s digital era. Automatic text summarization provides a quick summary to the user based on the information presented in the text documents. This paper presents the automated single document summarization by constructing similitude graphs from the extracted text segments. On extracting the text segments, the feature values are computed for all the segments by comparing them with the title and the entire document and by computing segment significance using the information gain ratio. Based on the computed features, the similarity between the segments is evaluated to construct the graph in which the vertices are the segments and the edges specify the similarity between them. The segments are ranked for including them in the extractive summary by computing the graph score and the sentence segment score. The experimental analysis has been performed using ROUGE metrics and the results are analyzed for the proposed model. The proposed model has been compared with the various existing models using 4 different datasets in which the proposed model acquired top 2 positions with the average rank computed on various metrics such as precision, recall, F-score.
HIGHLIGHTS
- Paper presents the automated single document summarization by constructing similitude graphs from the extracted text segments
- It utilizes information gain ratio, graph construction, graph score and the sentence segment score computation
- Results analysis has been performed using ROUGE metrics with 4 popular datasets in the document summarization domain
- The model acquired top 2 positions with the average rank computed on various metrics such as precision, recall, F-score
GRAPHICAL ABSTRACT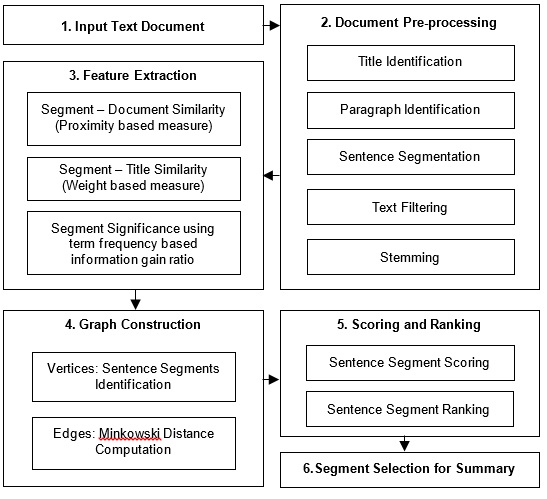
Downloads
References
R Nallapati, B Zhou, C Gulcehre, CND Santos and B Xiang. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In: Proceedings of the SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany. 2016, p. 280-90.
R Nallapati, B Zhou and M Ma. Classify or select: Neural architectures for extractive document summarization, Available at: https://arxiv.org/abs/1611.04244, accessed November 2020.
AM Rush, S Chopra and J Weston. A neural attention model for abstractive sentence summarization, Available at: https://arxiv.org/abs/1509.00685, accessed September 2020.
R Mihalcea and P Tarau. A language independent algorithm for single and multiple document summarization. In: Proceedings of the International Joint Conference on Natural Language Processing, Jeju Island, Korea. 2005, p. 19-24.
PD Turney. Learning algorithms for keyphrase extraction. Inform. Retrieval 2000; 2, 303-36.
M Litvak and M Last. Graph-based keyword extraction for single-document summarization. In: Proceedings of the Workshop Multi-source Multilingual Information Extraction and Summarization, Manchester, United Kingdom. 2008, p. 17-24.
G Erkan and D Radev. Lexpagerank: Prestige in multi-document text summarization. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain. 2004, p. 365-71.
R McDonald. A study of global inference algorithms in multi-document summarization. In: G Amati, C Carpineto and G Romano (Eds.). Advances in Information Retrieval. Springer, Berlin, Heidelberg, 2001, p. 557-64.
K Woodsend, Y Feng and M Lapata. Generation with quasi-synchronous grammar. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, Massachusetts, United Kingdom. 2010, p. 513-23.
R Socher, EH Huang, J Pennin, CD Manning and AY Ng. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection. In: Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain. 2011, p. 801-9.
M Kågebäck, O Mogren, N Tahmasebi and D Dubhashi. Extractive summarization using continuous vector space models. In: Proceedings of the 2nd Workshop on Continuous Vector Space Models and their Compositionality, Gothenburg, Sweden. 2014, p. 31-9.
R Nallapati, B Zhou and B Xiang. Sequence-to-sequence RNNs for text summarization, Available at: https://arxiv.org/pdf/1602.06023v1.pdf, accessed January 2020.
J Cheng and M Lapata. Neural summarization by extracting sentences and words. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany. 2016, p. 484-94.
O Sornil and K Gree-Ut. An automatic text summarization approach using content-based and graph-based characteristics. In: Proceedings of the IEEE Conference on Cybernetics and Intelligent Systems, Bangkok, Thailand. 2006, p. 1-6.
YA AL-Khassawneh, N Salim and OA Isiaka. Extractive text summarisation using graph triangle counting approach: Proposed method. In: Proceedings of the International Conference of Recent Trends in Information and Communication Technologies, Johor, Malaysia. 2014, p. 300-11.
T Mori. Information gain ratio as term weight: the case of summarization of IR results. In: Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan. 2002, p. 1-7.
S Chopra, M Auli and AM Rush. Abstractive sentence summarization with attentive recurrent neural networks. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, California. 2016, p. 93-8.
R Nallapati, F Zhai and B Zhou. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, California. 2017, p. 1684-90
A See, PJ Liu and CD Manning. Get to the point: Summarization with pointer-generator networks. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada. 2017, p. 1073-83.
J Tan, X Wan and J Xiao. Abstractive document summarization with a graph-based attentional neural model. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada. 2017, p. 1171-81.
Y Chen, Y Ma, X, Mao and Q Li. Multi-task learning for abstractive and extractive summarization. Data Sci. Eng. 2019; 4, 14-23.
D Zajic, B Dorr and R Schwartz. Bbn/umd at duc-2004: Topiary. In: Proceedings of the HLT-NAACL Document Understanding Workshop, Boston. 2004, p. 112-9
P Koehn, H Hoang, A Birch, C Callison-Burch, M Federico, N Bertoldi, B Cowan, W Shen, C Moran, R Zens and C Dyer. Moses: Open source toolkit for statistical machine translation. In: Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic. 2007, p. 177-80.
S Wubben, EJ Krahmer and AVD Bosch. Sentence simplification by monolingual machine translation. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea. 2012, p. 1015-24.
K Ganesan, C Zhai and J Han. Opinosis: A graph based approach to abstractive summarization of highly redundant opinions. In: Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China. 2010, p. 340-8.
H Lin and J Bilmes. A class of submodular functions for document summarization. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Oregon. 2011, p. 510-20.
R Collobert and J Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In: Proceedings of the 25th International Conference on Machine Learning, New York. 2008, p. 160-67.
T Mikolov, K Chen, G Corrado and J Dean. Efficient estimation of word representations in vector space, Available at: https://arxiv.org/abs/1301.3781, accessed January 2020.
T Mikolov, I Sutskever, K Chen, GS Corrado and J Dean. Distributed representations of words and phrases and their compositionality. In: Proceedings of the Conference on Advances in Neural Information Processing Systems, New York. 2013, p. 3111-9.
JM Torres-Moreno, PL St-Onge, M Gagnon, M El-Beze and P Bellot. Automatic summarization system coupled with a question-answering system (QAAS), Available at: https://arxiv.org/abs/0905.2990, accessed January 2020.
AAL Below. Information retrieval data structures and algorithms. Prentice Hall, New Jersey, 1992.
SS Bama, I Ahmed and A Saravanan. A mathematical approach for improving the performance of the search engine through web content mining. J. Theor. Appl. Inform. Tech. 2014; 60, 343-50.
SS Bama, MI Ahmed and A Saravanan. A mathematical approach for mining web content outliers using term frequency ranking. Indian J. Sci. Tech. 2015; 8, 1-5.
MF Porter. An algorithm for suffix stripping. Program Electron. Libr. Inform. Syst. 1980; 14, 130-7.
SS Bama, MSI Ahmed and A Saravanan. Relevance re-ranking through proximity based term frequency model. In: G Stojanov and A Kulakov (Eds.). Advances in Intelligent Systems and Computing. Springer, Cham, 2016, p. 216-29.
SS Bama, MI Ahmed and A Saravanan. Enhancing the search engine results through web content ranking. Int. J. Appl. Eng. Res. 2015; 10, 13625-35.
S Bertazzon and S Olson. Alternative distance metrics for enhanced reliability of spatial regression analysis of health data. In: Proceedings of the International Conference on Computational Science and Its Applications, Berlin, Germany. 2008, p. 361-74.
R Shahid, S Bertazzon, ML Knudtson and WA Ghali. Comparison of distance measures in spatial analytical modeling for health service planning. BMC Health Serv. Res. 2009; 9, 200.
SS Bama and A Saravanan. Efficient classification using average weighted pattern score with attribute rank based feature selection. Int. J. Intell. Syst. Appl. 2019; 11, 29-42.
KM Hermann, T Kocisky, E Grefenstette, L Espeholt, W Kay, M Suleyman and P Blunsom. Teaching machines to read and comprehend. In: Proceedings of the 28th International Conference on Neural Information Processing Systems, Massachusetts. 2016, p. 1693-701.
F Dernoncourt, M Ghassemi and W Chang. A repository of corpora for summarization. In: Proceedings of the 11th International Conference on Language Resources and Evaluation, Miyazaki, Japan. 2018, p. 3221-7.
CY Lin. Rouge: A package for automatic evaluation of summaries. In: Proceedings of the Workshop on Text Summarization Branches out, Barcelona, Spain. 2004. p. 74-81.
H Schütze, CD Manning and P Raghavan. An introduction to information retrieval. Vol 39. Cambridge University Press, Cambridge, England, 2009.
J Clarke and M Lapata. Global inference for sentence compression: An integer linear programming approach. J. Artif. Intell. Res. 2008; 31, 399-429.

Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.



