
Comparative Evaluation of Machine Learning Algorithms for Alzheimer’s Disease Classification using Synthetic Transcriptomics Dataset
DOI:
https://doi.org/10.48048/tis.2023.6881Keywords:
Alzheimer’s disease, High-dimensional data, Machine learning, Multi-omics, Simulations, TranscriptomicsAbstract
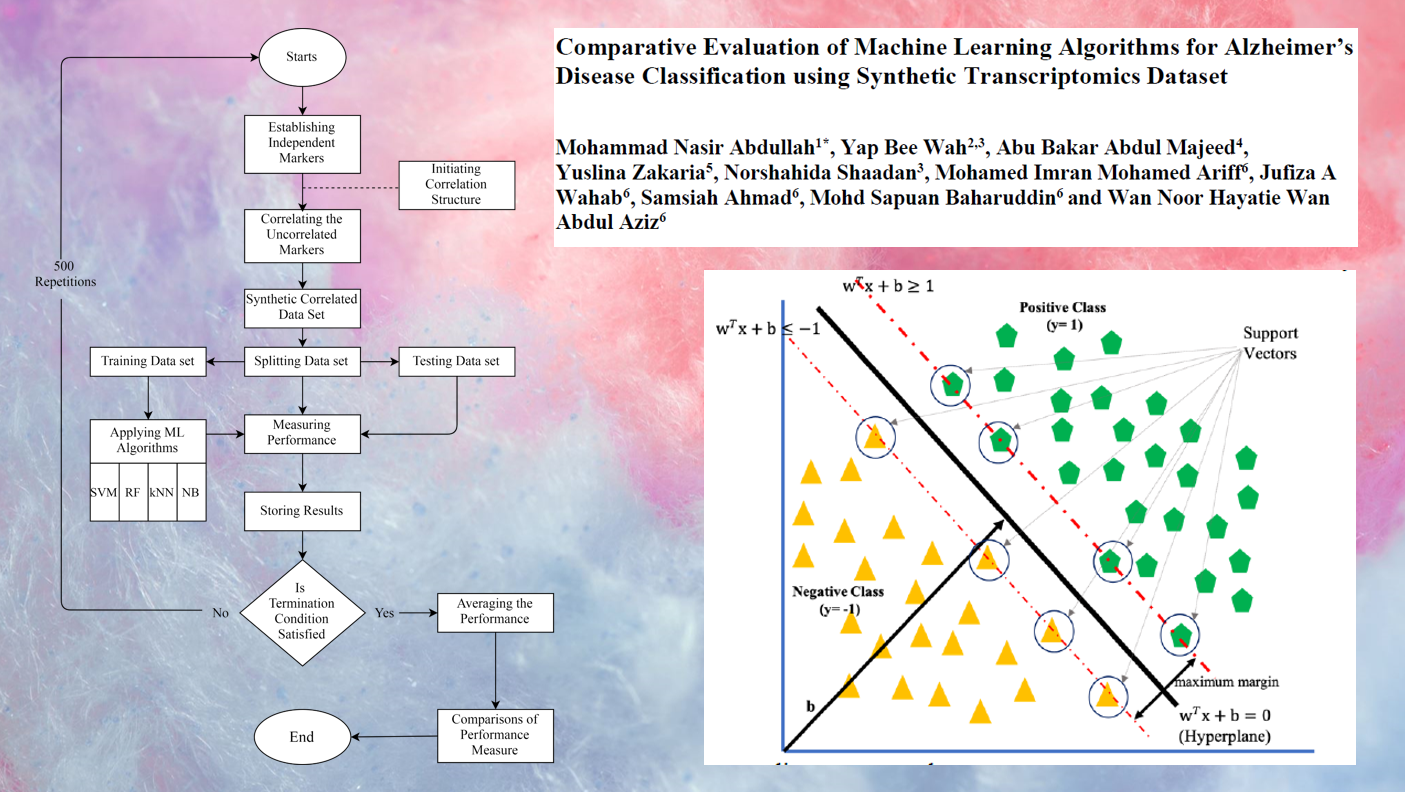
Recent technological advancements have enabled the understanding of multi-omics data, including transcriptomics, proteomics, and metabolomics. Machine learning algorithms have shown promising results in classifying multi-omics data. The objective of this paper is to evaluate the performance of machine learning algorithms in classifying transcriptomics data for Alzheimer’s disease (AD) patients and healthy control (HC) individuals. A Synthetic dataset of varying sample sizes, dimensionalities, effect sizes, and correlations was generated based on actual transcriptomics data for AD patients. The dataset consisted of 22,254 markers for 92 AD patients and 92 HC individuals. Four machine learning classifiers: naïve Bayes (NB), k-nearest neighbour (k-NN), support vector machine (SVM), and random forest (RF), were used to classify the data. The simulation was conducted using a parallel processing approach on a high-performance machine. Based on the error rate and F-measure, NB outperformed k-NN, SVM, and RF for high-dimensional data. However, SVM with a radial basis kernel (RBF) kernel performed better than NB only when the sample size was greater than 100 per group for all dimensions. The result suggests that machine learning algorithms, specifically NB, can effectively classify transcriptomics data for AD patients. SVM with an RBF kernel is a better option for large sample sizes. This study provides valuable insights for future research in the classification of transcriptomics data using machine learning algorithms.
HIGHLIGHTS
- The performance of machine learning algorithms in classifying transcriptomics data for Alzheimer’s disease (AD) patients and healthy control (HC) individuals
- A synthetic dataset of varying sample sizes, dimensionalities, effect sizes, and correlations was generated based on actual transcriptomics data for AD patients
- Four machine learning classifiers: Naïve Bayes (NB), k-nearest neighbour (k-NN), support vector machine (SVM), and random forest (RF), were used to classify the data
- Based on the error rate and F-measure, NB outperformed k-NN, SVM and RF for high dimensional data.
- SVM with a radial basis kernel (RBF) kernel performed better than NB only when the sample size was greater than 100 per group for all dimensions
GRAPHICAL ABSTRACT
Downloads
References
W Zhang, Y Zeng, M Jiao, C Ye, Y Li, C Liu and J Wang. Integration of high-throughput omics technologies in medicinal plant research: The new era of natural drug discovery. Front. Plant Sci. 2023; 14, 1073848.
W Chiu, J Schepers, T Francken, L Vangeel, K Abbasi, D Jochmans, SD Jonghe, HJ Thibaut, V Thiel, J Neyts, M Laporte and P Leyssen. Development of a robust and convenient dual-reporter high-throughput screening assay for SARS-CoV-2 antiviral drug discovery. Antiviral Res. 2023; 210, 105506.
SB Koby, E Gutkin, F Gusev, CM Narangoda, O Isayev and MG Kurnikova. High-throughput binding free energy simulations: Applications in drug discovery. Biophys. J. 2023; 122, 142a-143a.
G Romeo and M Thoresen. Model selection in high-dimensional noisy data: A simulation study. J. Stat. Comput. Simul. 2019; 89, 2031-50.
P Gong, L Cheng, Z Zhang, A Meng, E Li, J Chen and L Zhang. Multi-omics integration method based on attention deep learning network for biomedical data classification. Comput. Methods Programs Biomed. 2023; 231, 107377.
Z Liu, Y Zhao, P Kong, Y Liu, J Huang, E Xu, W Wei, G Li, X Cheng, L Xue, Y Li, H Chen, S Wei, R Sun, H Cui, Y Meng, M Liu, Y Li, R Feng, X Yu, R Zhu, Y Wu, L Li, B Yang, Y Ma, J Wang, W Zhu, D Deng, Y Xi, F Wang, H Li, S Guo, X Zhuang, X Wang, Y Jiao, Y Cui and Q Zhan. Integrated multi-omics profiling yields a clinically relevant molecular classification for esophageal squamous cell carcinoma. Cancer Cell 2023; 41, 181-95.
Y Chen, J Meng, X Lu, X Li and C Wang. Clustering analysis revealed the autophagy classification and potential autophagy regulators’ sensitivity of pancreatic cancer based on multi-omics data. Cancer Med. 2023; 12, 733-46.
SA Qureshi, L Hussain, U Ibrar, E Alabdulkreem, MK Nour, MS Alqahtani, FM Nafie, A Mohamed, GP Mohammed and TQ Duong. Radiogenomic classification for MGMT promoter methylation status using multi-omics fused feature space for least invasive diagnosis through mpMRI scans. Sci. Rep. 2023; 13, 3291.
G Zararsiz, D Goksuluk, S Korkmaz, V Eldem, GE Zararsiz, IP Duru and A Ozturk. A comprehensive simulation study on classification of RNA-Seq data. PLoS One 2017; 12, e0182507.
J Fan and R Li. Statistical challenges with high dimensionality: Feature selection in knowledge discovery. In: Proceedings of the International Congress of Mathematicians, Madrid, Spain. 2006, p. 595-622.
M Khondoker, R Dobson, C Skirrow, A Simmons and D Stahl. A comparison of machine learning methods for classification using simulation with multiple real data examples from mental health studies. Stat. Methods Med. Res. 2016; 25, 1804-23.
CA Bobak, AJ Titus and JE Hill. Comparison of common machine learning models for classification of tuberculosis using transcriptional biomarkers from integrated datasets. Appl. Soft Comput. J. 2019; 74, 264-73.
DA Gredell, AR Schroeder, KE Belk, CD Broeckling, AL Heuberger, SY Kim, DA King, SD Shackelford, JL Sharp, TL Wheeler, DR Woerner and JE Prenni. Comparison of machine learning algorithms for predictive modeling of beef attributes using rapid evaporative ionization mass spectrometry (REIMS) data. Sci. Rep. 2019; 9, 5721.
T Ma, and A Zhang. Integrate multi-omics data with biological interaction networks using Multi-view Factorization AutoEncoder (MAE). BMC Genom. 2019; 20, 944.
G Albuquerque, T Lowe and M Magnor. Synthetic generation of high-dimensional datasets. IEEE Trans. Vis. Comput. Graph. 2011; 17, 2317-24.
DS Quintana. A synthetic dataset primer for the biobehavioural sciences to promote reproducibility and hypothesis generation. eLife 2020; 9, e53275.
K Moradzadeh, S Moein, N Nickaeen and Y Gheisari. Analysis of time-course microarray data: Comparison of common tools. Genomics 2019; 111, 636-41.
J Andrade and J Duggan. An evaluation of Hamiltonian Monte Carlo performance to calibrate age-structured compartmental SEIR models to incidence data. Epidemics 2020; 33, 100415.
B Hanczar and E Dougherty. On the comparison of classifiers for microarray data. Curr. Bioinform. 2010; 5, 29-39.
S Rogers and M Girolami. A first course in machine learning. CRC Press, Florida, 2016.
Ahmed, Shahjaman, MM Rana and MNH Mollah. Robustification of naïve Bayes classifier and its application for microarray gene expression data analysis. Biomed. Res. Int. 2017; 2017, 3020627.
CR Stephens, HF Huerta, and AR Linares. When is the Naive Bayes approximation not so naive? Mach. Learn. 2018; 107, 397-441.
B Chandra and M Gupta. Robust approach for estimating probabilities in Naïve-Bayes classifier for gene expression data. Expet. Syst. Appl. 2011; 38, 1293-8.
J Liu and S Bo. Naive Bayesian classifier based on genetic simulated annealing algorithm. Proc. Eng. 2011; 23, 504-9.
DD Lewis. Naive (Bayes) at forty: The independence assumption in information retrieval. In: C Nédellec and C Rouveirol (Eds.). European conference on machine learning. Springer Berlin, Heidelberg, 1998, p. 4-15.
L Zhang, C Lv, Y Jin, G Cheng, Y Fu, D Yuan, Y Tao, Y Guo, X Ni and T Shi. Deep learning-based multi-omics data integration reveals two prognostic subtypes in high-risk neuroblastoma. Front. Genet. 2018; 9, 477.
Z Ahmed. Practicing precision medicine with intelligently integrative clinical and multi-omics data analysis. Hum. Genom. 2020; 14, 35.
Y Gao, R Zhou and Q Lyu. Multiomics and machine learning in lung cancer prognosis. J. Thorac. Dis. 2020; 12, 4531-5.
E Fix, JL Hodges and Jr. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. 1989; 57, 238-47.
J Gou, L Du, Y Zhang and T Xiong. A new distance-weighted k-nearest neighbor classifier. J. Inform. Comput. Sci. 2012; 9, 1429-36.
J Hua, Z Xiong, J Lowey, E Suh and ER Dougherty. Optimal number of features as a function of sample size for various classification rules. Bioinformatics 2005; 21, 1509-15.
M Kuhkan. A method to improve the accuracy of k-nearest neighbor algorithm. Int. J. Comput. Eng. Inf. Tech. 2016; 8, 90-5.
J Luengo, S García, I Triguero, J Maillo, F Herrera and D García-Gil. Transforming big data into smart data: An insight on the use of the k-nearest neighbors algorithm to obtain quality data. Wiley Interdiscipl. Rev. Data Min. Knowl. Discov. 2018; 9, e1289.
S Draghici. Data analysis tools for DNA microarrays. Chapman and Hall/CRC, New York, 2003.
X Dong, L Lin, R Zhang, Y Zhao, DC Christiani, Y Wei and F Chen. TOBMI: Trans-omics block missing data imputation using a k-nearest neighbor weighted approach. Bioinformatics 2019; 35, 1278-83.
M Song, J Greenbaum, J Luttrell, W Zhou, C Wu, H Shen, P Gong, C Zhang and HW Deng. A review of integrative imputation for multi-omics datasets. Front. Genet. 2020; 11, 570255.
QR Xing, NO Cipta, K Hamashima, YC Liou, CG Koh and YH Loh. Unraveling heterogeneity in transcriptome and its regulation through single-cell multi-omics technologies. Front. Genet. 2020; 11, 662.
DA Cusanovich, AJ Hill, D Aghamirzaie, RM Daza, HA Pliner, JB Berletch, GN Filippova, X Huang, L Christiansen, WSD Witt, C Lee, SG Regalado, DF Read, FJ Steemers, CM Disteche, C Trapnell and J Shendure. A single cell atlas of in vivo mammalian chromatin accessibility. Cell 2019; 174, 1309-24.
S Karimi, AA Sadraddini, AH Nazemi, T Xu and AF Fard. Generalizability of gene expression programming and random forest methodologies in estimating cropland and grassland leaf area index. Comput. Electron. Agr. 2018; 144, 232-40.
W Chen, X Xie, J Wang, B Pradhan, H Hong, DT Bui, Z Duan and J Ma. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017; 151, 147-60.
L Breiman. Random forests. Mach. Learn. 2001; 45, 5-32.
AJ Sage, 2018. Random forest robustness, variable importance, and tree aggregation. Ph. D. Dissertation. Iowa State University, Iowa.
TM Oshiro, PS Perez and JA Baranauskas. How many trees in a random forest? In: P Perner (Ed.). International workshop on machine learning and data mining in pattern recognition. Springer Berlin, Heidelberg, 2012, p. 154-68.
M Pal. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005; 26, 217-22.
L Rutkowski, M Jaworski, L Pietruczuk and P Duda. The CART decision tree for mining data streams. Inform. Sci. 2014; 266, 1-15.
MN Abdullah, BW Yap and Y Zakaria. Metabolites selection and classification of metabolomics data on Alzheimer’s disease using random forest. In: M Berry, AH Mohamed and B Yap (Eds.). Communications in Computer and Information Science. Springer, Singapore. 2016
A Acharjee, B Kloosterman, RGF Visser and C Maliepaard. Integration of multi-omics data for prediction of phenotypic traits using random forest. BMC Bioinformatics 2016; 17, 363-73.
IN Jamil, J Remali, KA Azizan, NA Nor Muhammad, M Arita, HH Goh and WM Aizat. Systematic Multi-Omics Integration (MOI) approach in plant systems biology. Front. Plant Sci. 2020; 11, 944.
N Holzscheck, J Söhle, B Kristof, E Grönniger, S Gallinat, H Wenck, M Winnefeld, C Falckenhayn and L Kaderali. Multi-omics network analysis reveals distinct stages in the human aging progression in epidermal tissue. Aging 2020; 12, 12393-409.
W Tao, AN Concepcion, M Vianen, ACA Marijnissen, FPGJ Lafeber, TRDJ Radstake and A Pandit. Multi‐omics and machine learning accurately predicts clinical response to Adalimumab and Etanercept therapy in patients with rheumatoid arthritis. Arthritis Rheumatol. 2021; 71, 212-22.
NA Bokulich, P Łaniewski, DM Chase, J Gregory Caporaso and MM Herbst-Kralovetz. Integration of multi-omics data improves prediction of cervicovaginal microenvironment in cervical cancer. PLoS Comput. Biol. 2022; 18, e1009876.
VN Vapnik. The nature of statistical learning theory. Springer, New York, 2000.
R Kharoubi, K Oualkacha and A Mkhadri. The cluster correlation-network support vector machine for high-dimensional binary classification. J. Stat. Comput. Simul. 2019; 89, 1020-43.
B Ghaddar and J Naoum-Sawaya. High dimensional data classification and feature selection using support vector machines. Eur. J. Oper. Res. 2018; 265, 993-1004.
N Cristianini and J Shawe-Taylor. An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge, 2014.
Liming Shen, H Chen, Z Yu, W Kang, B Zhang, H Li, B Yang and D Liu. Evolving support vector machines using fruit fly optimization for medical data classification. Knowledge Based Syst. 2016; 96, 61-75.
M Singh and AG Shaik. Faulty bearing detection, classification and location in a three-phase induction motor based on Stockwell transform and support vector machine. Meas. J. Int. Meas. Confed. 2019; 131, 524-33.
S Huang, CAI Nianguang, PP Pacheco, S Narandes, Y Wang and XU Wayne. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteomics 2018; 15, 41-51.
AJ Smola and BSCH Olkopf. A tutorial on support vector regression. Stat. Comput. 2004; 14, 199-222.
B Ray, W Liu and D Fenyo. Adaptive multiview nonnegative matrix factorization algorithm for integration of multimodal biomedical data. Cancer Inform. 2017; 16, 1-12.
QA Hathaway, SM Roth, MV Pinti, DC Sprando, A Kunovac, AJ Durr, CC Cook, GK Fink, TB Cheuvront, JH Grossman, GA Aljahli, AD Taylor, AP Giromini, JL Allen and JM Hollander. Machine-learning to stratify diabetic patients using novel cardiac biomarkers and integrative genomics. Cardiovasc. Diabetol. 2019; 18, 78.
B Ma, F Meng, G Yan, H Yan, B Chai and F Song. Diagnostic classification of cancers using extreme gradient boosting algorithm and multi-omics data. Comput. Biol. Med. 2020; 121, 103761.
Y Liu, F Liu, X Hu, J He, and Y Jiang. Combining genetic mutation and expression profiles identifies novel prognostic biomarkers of lung adenocarcinoma. Clin. Med. Insights Oncol. 2020; 14, 1-10.
S Ma, J Ren and D Fenyö. Breast cancer prognostics using multi-omics data. AMIA Jt. Summits Transl. Sci. Proc. 2016; 52, 52-9.
J Hardin, SR Garcia and D Golan. A method for generating realistic correlation matrices. Ann. Appl. Stat. 2013; 7, 1733-62.
Y Zhang, QV Liao and B Srivastava. Towards an optimal dialog strategy for information retrieval using both open- and close-ended questions. In: Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan.
SAP Parambath, N Usunier and Y Grandvalet. Optimizing F-measures by cost-sensitive classification. In: Z Ghahramani, M Welling, C Cortes, N Lawrence and KQ Weinberger (Eds.). advances in neural information processing systems 27, Curran, New York, 2014.
R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria, 2018.
RStudio Team. RStudio: Integrated development environment for R. RStudio, PBC, Boston, MA, 2021, Available: http://www.rstudio.com, accessed December 2022.
D Meyer, E Dimitriadou, K Hornik, A Weingessel, F Leisch, CC Chang, CC Lin and MD Meyer. Package e1071, Available at: https://cran.r-project.org/web/packages/e1071/index.html, accessed December 2022.
M Kuhn. Building predictive models in R using the caret package. J. Stat. Software 2018; 28, 1-26.
A Liaw and M Wiener. Classification and regression by random forest. R News 2002; 2, 18-22.
S Weston. Using the foreach package. R Foundation for Statistical Computing, Vienna, Austria, 2017.
R Calaway, S Weston and D Tenenbaum. doParallel, Available: https://cran.r-project.org/package=doParallel, accessed December 2022.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Walailak University

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.



