
Natural Disaster on Twitter: Role of Feature Extraction Method of Word2Vec and Lexicon Based for Determining Direct Eyewitness
DOI:
https://doi.org/10.48048/tis.2021.680Keywords:
Feature extraction, Natural disaster, Text classification, Word2vec, LexiconAbstract
Researchers have collected Twitter data to study a wide range of topics, one of which is a natural disaster. A social network sensor was developed in existing research to filter natural disaster information from direct eyewitnesses, none eyewitnesses, and non-natural disaster information. It can be used as a tool for early warning or monitoring when natural disasters occur. The main component of the social network sensor is the text tweet classification. Similar to text classification research in general, the challenge is the feature extraction method to convert Twitter text into structured data. The strategy commonly used is vector space representation. However, it has the potential to produce high dimension data. This research focuses on the feature extraction method to resolve high dimension data issues. We propose a hybrid approach of word2vec-based and lexicon-based feature extraction to produce new features. The Experiment result shows that the proposed method has fewer features and improves classification performance with an average AUC value of 0.84, and the number of features is 150. The value is obtained by using only the word2vec-based method. In the end, this research shows that lexicon-based did not influence the improvement in the performance of social network sensor predictions in natural disasters.
HIGHLIGHTS
- Implementation of text classification is generally only used to perform sentiment analysis, it is still rare to use it to perform text classification for use in determining direct eyewitnesses in cases of natural disasters
- One of the common problems in text mining research is the extracted features from the vector space representation method generate high dimension data
- A hybrid approach of word2vec-based and lexicon-based feature extraction experiment was conducted in order to find a method that can generate new features with low dimensions and also improve the classification performance
GRAPHICAL ABSTRACT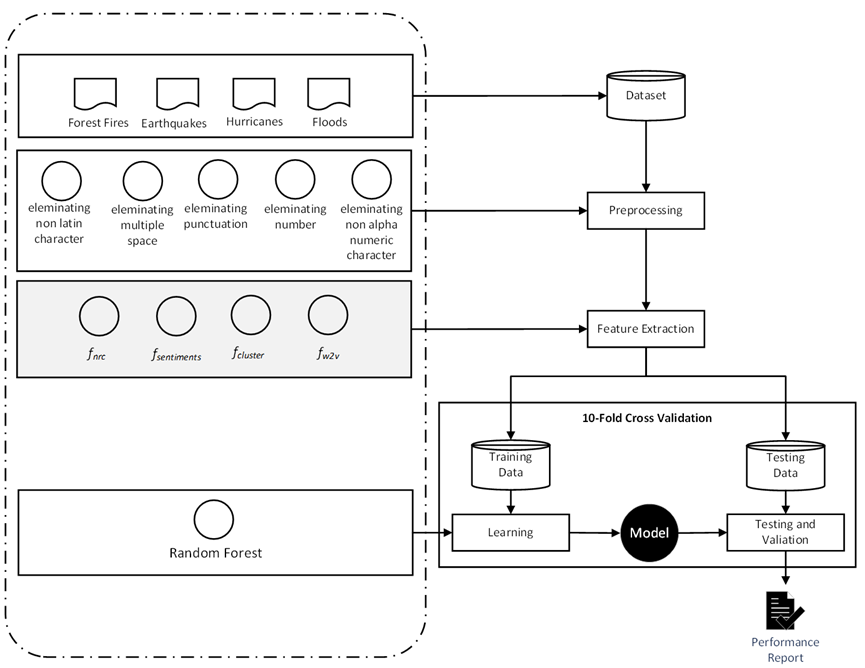
Downloads
References
Y Kryvasheyeu, H Chen, E Moro, P Van Hentenryck and M Cebrian. Performance of social network sensors during hurricane sandy. PLoS One 2015; 10, 1-19.
NA Christakis and JH Fowler. Social network sensors for early detection of contagious outbreaks. PLoS One 2010; 5, e12948-e12948.
K Zahra, M Imran, and FO Ostermann. Automatic identification of eyewitness messages on twitter during disasters. Inf. Process. Manag. 2020; 57, 102107.
MR Faisal, B Abapihi, NG Nguyen, B Purnama, MK Delimayanti, D Phan, FR Lumbanraja, M Kubo and K Satou. Improving protein sequence classification performance using adjacent and overlapped segments on existing protein descriptors. J. Biomed. Sci. Eng. 2018; 11, 126-43.
M Imran, P Mitra and C Castillo. Twitter as a lifeline: Human-annotated Twitter corpora for NLP of crisis-related messages. In: Proceedings of the 10th International Conference on Language Resources and Evaluation, LREC 2016 - Portoroz, Slovenia. 2016, p. 1638-43.
N Tarmizi, S Saee, D Hanani and A Ibrahim. Author identification for under-resourced language Kadazandusun. Indonesian J. Electr. Eng. Comput. Sci. 2020; 17, p. 248-55.
K Orkphol and W Yang. Word Sense Disambiguation Using Cosine Similarity Collaborates with Word2vec and WordNet. Future Internet 2019; 11, 114.
F Nurifan, R Sarno and CS Wahyuni. Developing corpora using word2vec and wikipedia for word sense disambiguation. Indonesian J. Electr. Eng. Comput. Sci. 2018; 12, 1239-46.
H Li and X Li, D Caragea and C Caragea. Comparison of word embeddings and sentence encodings as generalized representations for crisis tweet classification tasks. In: Proceedings of the Information Systems for Crisis Response and Management Asia Pacific Conference, Wellington, New Zealand, 2018.
PD Turney and ML Littman. Measuring praise and criticism: Inference of semantic orientation from association. ACM Trans. Inf. Syst. 2003; 21, 315-46.
SM Mohammad and PD Turney. Crowdsourcing a word-emotion association lexicon. Comput. Intell. 2013; 29, 436-65.
M Hu and B Liu. Mining and summarizing customer reviews. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, USA. 2004, p. 168-77.
L Wu, F Morstatter and H Liu. SlangSD: Building, expanding and using a sentiment dictionary of slang words for short-text sentiment classification. Lang. Resour. Eval. 2018; 52, 839-52.
MA Ayu, SS Wijaya and T Mantoro. An automatic lexicon generation for Indonesian news sentiment analysis: A case on governor elections in Indonesia. Indonesian J. Electr. Eng. Comput. Sci. 2019; 16, 1555-61.
S Baccianella, A Esuli and F Sebastiani. SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In: Proceedings of Proceedings of the 7th International Conference on Language Resources and Evaluation, Valletta, Malta. 2010.
B Schmidt and J Li. WordVectors: Tools for creating and analyzing vector-space models of texts. R package version 2.0, Available at: http://github.com/bmschmidt/wordVectors, accessed May 2020.
TW Rinker. 2019, Sentiment: Calculate text polarity sentiment. Buffalo, New York, Available at: http://github.com/trinker/sentimentr, accessed May 2020.
R Core Team. R: A language and environment for statistical computing. Vienna, Austria. Available at: https://www.r-project.org, accessed May 2020.
A Liaw and M Wiener. Classification and regression by random forest. R. News. 2002; 2, 18-22.
X Robin, N Turck, A Hainard, N Tiberti, F Lisacek, JC Sanchez and M Müller. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011; 12, 77.
L Breiman. Random forests. Mach. Learn. 2001; 45, 5-32.
T Mikolov, K Chen, G Corrado and J Dean. Efficient estimation of word representations in vector space. Available at: https://arxiv.org/abs/1301.3781, accessed April 2020.
F Murtagh and P Legendre. Ward’s hierarchical agglomerative clustering method: Which algorithms implement Ward’s criterion? J. Classif. 2014; 31, 274-95.
T Mikolov, I Sutskever, K Chen, GS Corrado and J Dean. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013; 2, 3111-19.
J Ward. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963; 58, 236-44.
F Gorunescu. Data mining: Concepts, models and techniques. Vol XII. Springer, Berlin, 2011.

Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.



